大家好!我是贾瑶琪,Parity亚洲区工程总监,主要负责技术研发和Substrate开发者生态建设。今天我将和大家分享区块链里难度比较大但很有意思的两个话题,一个是可扩展性,另一个是互操作性。今天讲的内容更偏技术一些,我会举一些例子帮助大家去理解里面的技术细节。
Web3.0定义和应用

Web3.0是目前一个比较热门的概念,许多从事区块链行业的人也会认为自己开发的应用是面向Web3.0的。究竟什么是Web3.0呢?Web3.0有很多不同的定义,上图采纳了其中的一个。Web1.0时代,网页是只读的,用户只能搜集信息,浏览信息。Web2.0时代是社交网络的时代,像脸书、推特、人人、新浪、微信,以及最新的快手、抖音等等。作为用户的我们不仅可以浏览,还可以自己创建内容并上传到网上。Web3.0更往前一步,除了可以发布内容,未来可以去做更多去中介化的事情。这样就不得不提到其中需要的一些方法,包括一些理念。
Web2.0时代数据被大公司控制,像谷歌、脸书以及亚马逊。当你使用他们的服务的时候,协议中写明可以免责使用你的数据。虽然谷歌早期的slogan是don’t do evil, 但是有时候却把自己的数据提供给第三方。在Web 3.0的时代,我们不需要他们保证don’t do evil,而是通过代码使他们can’t do evil。
Web3.0时代,为了实现愿景,需要什么样的技术呢?区块链是一个基础。区块链可以提供的特性,一是不可篡改,二是公开透明,三是点对点的网络。
再具体到一些细节如Web3.0技术栈,简单的可以划分为这几层,最上层是客户端,比如去中心化的浏览器。在这之下包含了一些协议支持的开发工具,对应API和特定编程语言。脸书的Libra有自己的编程语言Move,以太坊也有自己的编程语言Solidity。再下一层是Layer2的协议,比如说Governance、State channels等。一个区块链应用不能随意获取互联网上的信息,比如说想看天气预报,区块链不能直接提供这样的数据,这里我们就需要Layer2协议栈中预言机协议,通过协议本身预言机机制获取互联网上的信息放在区块链上。Layer1协议,就是广为人知的区块链底层协议,比特币、以太坊等各种各样的公链,联盟链都采用了类似的底层协议,它提供了支撑整个Web3.0愿景的基础。再往下是网络层,如P2P网络传输。
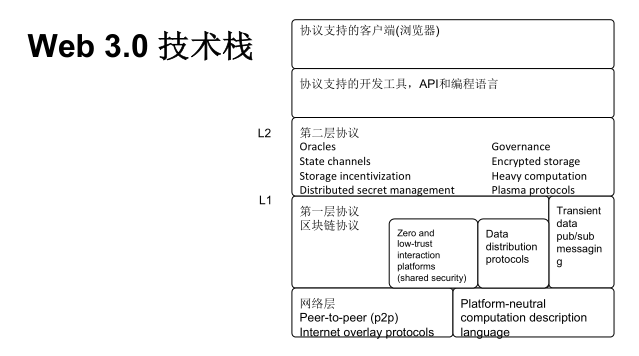
有了这样的技术栈,才使得web3.0之路变得更加现实。在众多的Layer1协议中,Polkadot的跨链协议拥有很多优势,比如共享安全、互操作性等。Polkadot本身是基于Parity开源的Substrate开发的。Substrate作为一个通用的区块链开发框架,既可以用来开发Layer1协议如跨链操作,也可以用来实现Layer2协议如预言机。
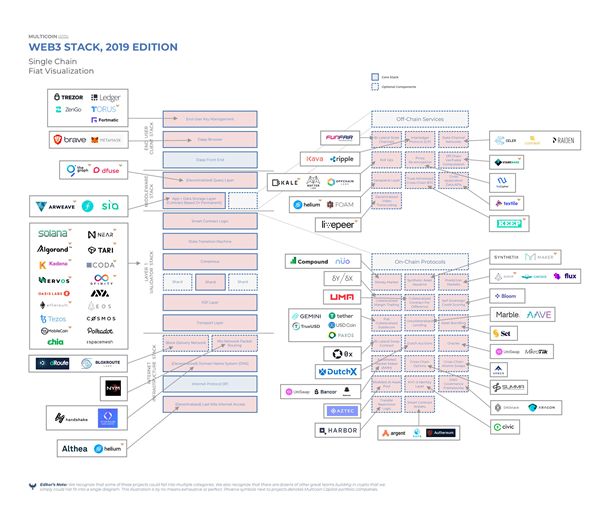
基于以上介绍的技术栈实现的早期应用有哪些呢?上图列出了一些典型的的Web3.0应用。除了大家熟悉的公链系统外,还有一些网络协议层的项目,更多的位于应用层,例如去中心的金融服务如借贷。但对于非区块链领域的用户,有没有真正的主流应用呢?目前其实没有。是什么导致现在没有主流的应用呢?在这里举几个例子进行解释。
案例一,以太小怪兽。这是一两年前在以太坊上特别流行的游戏应用。它的方法跟电子怪兽一样,你去购买这样一个怪兽去跟其它的怪兽进行打斗,如果赢的话可以升级。游戏在初期很火爆,但是后来发现这个游戏太花钱了。如果把一个小怪兽升到四级要花15美金的交易费,一直支撑他打怪兽或者进行训练。
案例二,以太猫。一两年前比较火爆,大家可以购买各种各样的加密猫,两个加密猫可以再生成一个新的加密猫。最火爆的时候,有的加密猫价值十万美金。但是也有问题。玩儿的人越多,手续费增加越高,因为以太坊的吞吐量只有这么多,如果大家想玩,需要用更高的手续费买到这样一个加密猫,同时出生费也相应增加。现在加密猫应用已经淡出人们的视线。
总结出来的一个结论是,目前对于区块链行业,由于低吞吐量带来的高手续费,给开发DApp带来很多功能限制。
可扩展性
无论是学术界还是产业界都致力于解决区块链低吞吐量的问题。其中一个方法是增加区块大小。如果把区块大小增加,吞吐量会有一个提升。但是由于带宽限制,这不是个提升吞吐量的高效(100倍)解决方案。
方案二,通过链下交易。链下处理所有交易,将结算部分上链。因为可以使用中心化的服务器处理交易,那么可以轻松实现每秒上千/万笔交易。通过这样的方式可以有效提高吞吐量。但是也有劣势,因为不是所有交易都在链上完成,那么中心化的服务器本身会不会进行一些作弊?透明度是个问题。
方案三,我们不再采用链式的数据结构,而是采用图结构,不同的节点可以生产不同的区块进行广播。当一个节点想打包区块的时候,可以基于过去的区块,建立一个有向无环图,再打包分发给其它节点。好处是可以包含多种交易,同时提高吞吐量。在图结构里面可能很多交易是有冲突的,对于最终要执行的智能合约是有分歧的,这就是图结构所遇到的难题。
方案四,代理人机制。参与共识协议的节点越少,跑起来越快,吞吐量越高。只有少量的超级节点参与共识协议可以达到一个高吞吐量,但是容易被大家垢病的是少量的代理节点能否代表整个社区。如果节点越少,这些节点不太喜欢某一些交易或者某一些应用,其实可以拒绝这个应用提交的交易。这就回到了中心化的弊端。
还有,就是分片以及多链。这个解决方案代表了一个趋势,在不损失很多去中心化特性的同时,可以达到比较好的吞吐量。大家看到最新的以太坊2.0和新的分片项目,还有一些跨链项目,大家会发现这中间的区别已经变得很模糊,很多时候可以把一个分片看成一个同构的链。在处理多链跨链交易的原子性协议和分片协议里面提到的原子性协议区别不大,有的采用同样的技术。只不过多链技术以及分片技术,有的时候会有一个中继链或者中继分片来协调不同的分片或者不同的链。但是归根到底,技术本身其实有很多相似的地方,这里统一起来进行讲解。
分片就是将交易分而治之,从而提高吞吐量。举个例子,有一千道问题,同时有一百个人解决问题。现在可以分组,一百个人分成十个小组,将一千道问题分给十个小组,每个小组十个人处理一百道问题,根据绝大多数人的答案形成一个共识,那么我们其实可以保证每个小组正确的解决一百道问题,这样整个解决时间就从一千减小到一百。未来如果有更多的听众,例如一千个,我们可以把一千人分成一百个小组,一百小组解决一千个问题,一个小组只解决十个问题,最终只用解决十个问题的时间把一千个问题都解决了。然而可能会出现一些攻击情形,假如如果有十个攻击者,他们合谋分到第一个小组,达成共识的时候不遵循一些原则,例如把一分钱掰成一万块人民币来进行双花攻击。如果攻击者能控制一个分片,产生的攻击在一些协议里面其它分片是不能进行阻止的。
如何避免这样的攻击呢?
首先,要设立很高的门槛,让攻击者不容易加入到网络中,防止女巫攻击。一个方法就是工作量证明,需要使用特定的矿机做足够时间的计算,才能作为节点提交区块。第二个方法,权益证明。
一旦有了一百个听众(或节点),进行随机分组可以保证听众分到不同的小组。我们需要根据一个什么样的随机数进行分组呢?一种方法是用上一个工作量证明的结果作为随机数将大家分到不同的小组。另外一个方法,在权益证明中,使用随机数生成协议(如VRF),让大家分到不同的分片里面。
如果已经有了比较合理的分组,且每个分组能保证正常节点占绝大多数,那么之后就是如何将上面提到的一千个问题分给不同组。为了保证不同的分片或者整个系统的数据一致性及有效性,我们需要一个方法来防止同一个交易被不同分片处理多次或者同一个数据被改变多次。常用解决方案是用两段式提交协议保证数据一致性。
刚刚讲到网络分片,节点可以安全的分到不同的分片或者链里面,之后的交易也可以分到不同的分片里,然后来进行交易处理,同时保证数据的有效性及一致性。如果做状态分片例如ETH2.0,每个分片有自己的数据存储,不同的分片存储不同的数据,这样会有单个分片数据丢失的风险。
比较直观的解决方法,首先就是通过一些权益奖励,鼓励节点长期在线,而且要做大量交易验证和共识协议来保证不会受到惩罚。如果长期掉线会被移出分片,而且抵押的权益会被系统拿走。当我们有了健壮的分片系统,那么我们可以整合多个分片或者链的吞吐量,从而极大地提升整个系统的吞吐量。
有了分片和多链的方法之后,我们更多想的是对于单链有哪些方法可以进一步提高它的吞吐量呢?更快的解决方法就是通过更改共识协议。目前比特币或者以太坊使用中本聪共识协议,节点通过工作量证明,每过一段时间生成一个区块,并将区块广播给其它节点,其它节点看到这个区块的时候,会选择拥有最长链的区块来进行确认。中本聪共识协议的优点是去中心化和异步。即使有上万个节点在网络里面,而且有不同的网络延迟,中本聪共识协议还是可以很好的在全网达成共识。当然缺点就是吞吐量太低。
拜占廷共识协议(BFT),是学术界产业界常用的共识协议。简单来讲,比如现在我要去买一张票,我要保证现场一百个人中的绝大多数都知道我要买票,大家都同意我买票。我的做法是广播给所有人,我要去买票的信息。其他人收到这样一个消息之后,同意这个信息,再把这个信息广播出去。当每个人收到2/3节点的确认信息之后,再广播一个自己收到绝大都数人确认的确认信息。当每个人收到2/3节点的最终确认信息之后,就确定了全网已经同意并确认买票的这个消息。
拜占庭共识协议的优势是速度快,如果去实现这样一个BFT控制协议很容易达到超过1000TPS,而且有绝对的最终性,一旦协议跑完,交易马上可以确认最终性。
缺点是传统拜占庭共识协议只能用于不到一百个节点,超过一百个节点,信息交换量太过庞大使得网络拥塞不能提升吞吐量。与此同时,它不是完全异步的。每个阶段都有一个等待时间,例如中间可以等十秒,如果没到就进行下一个阶段。如果长时间协议没有向前推进,就会进行视图转换,切换指挥者重新运行协议。
Polkadot整合和改进了中本聪共识协议和拜占庭共识协议。它采用了一个混合式的算法, GRANDPA协议和BABE协议。BABE协议是负责区块生成,GRANDPA协议是提供最终性的。BABE协议和传统的比特币、以太坊的协议一样。每过几秒钟选择一个节点进行出块,节点出块以后,进行一个广播,再过几秒选第二个节点进行一个出块,不同的节点也是根据最长链原则选择区块进行确认。
GRANDPA算法,它是根据BFT进行改进的版本,是非异步的共识协议。BABE协议生成的区块,GRANDPA协议最终会做一个敲定。BABE协议生成不同长度的链,GRANDPA协议会选择这里面包含最多投票的有效链进行确认。以往的区块链里面,如果进行共识协议,通常是一个块一个块进行敲定,但是Polkadot是根据不同的链进行敲定。比如每过一段时间,生成十个区块或者二十个区块,那么运行GRANDPA协议,将二十个区块直接一次性的确认。这样GRANDPA可以在有限的时间里确认更多的区块。
通过以上讲解,我们可以看到想要吞吐量高的区块链解决方案,同时拥有比较好的去中心化特性,最好的方法就是选择高吞吐量的单链解决方案加上安全高效的分片或者跨链解决方案。
互操作性
除了从可扩展性的角度出发,我们也需要从实际角度出发思考,为什么需要互操作性,或者为什么需要跨链。传统来讲,区块链可以解决信任的问题,如果可拓展性可以被解决,那么性能的问题也将被解决。互操作性其实是在上面两个问题被解决的情况下,可以解决更广泛的信任问题。
目前不同的应用场景有不同的联盟链和公有链。有了这些链之后,我们需要用互通性才能将有用的数据沟通起来。这里会涉及到跨链或者互操作性的不同方法。未来会看到一个界限极其模糊的区块链系统,就是私有链、联盟链、公链通过某种方式来进行互联。
区块链领域的互操作性,为什么在传统的互联网应用里不明确提这样的要求呢?因为现在的互联网基础设施已经把这些功能都提供好了,例如各种各样的SDK和API。你如果做一个应用想调用微信上面的数据,那么可以通过微信上面的SDK和接口把数据拿下来。如果想做支付,支付宝也有对应的支付通道,写代码的时候可以把API调用一下就可以做支付了。目前在区块链上无法做到的原因,是由于各种区块链不同的共识协和区块结构导致了我们的数据目前还是属于孤岛状态。为了让不同的孤岛上面的数据进行沟通,我们必须通过互操作性以及跨链的系统将不同的区块链连通起来。
互操作性以及跨链协议有哪些具体的方式呢?第一种方式就是公证人模式,不同链之间有一个公证人。相对比较去中心化的第二种方式就是侧链模式。通过侧链的方式,在链B上面可以验证链A上哪些交易被写到区块里,那么链B就可以验证A上面的操作并在B上面进行对应操作例如转账。第三种方式是哈希时间锁,这是相对一个比较复杂的协议,它是一个集去中心化以及透明交易的资产转换为一体的跨链操作。简单来讲,如果我做比特币兑换以太坊的交易,我在比特币这边放一个锁,同时对方也要在以太坊放一个锁。我把密钥给他,同样的密钥我可以获得对应的以太坊,同时他可以根据密钥获得对应的比特币。还有一个时间锁,保证双方只能在限定时间内去解锁以太坊和比特币,否则协议会自动终止,双方都没有获得对方的资产。
刚刚提到的方法都是很好的数字资产跨链的解决方案,无论是从效率还是去中心化的角度。如果想做到数据以及逻辑层面上的跨链,我们就需要更复杂的系统,例如多链系统里面的中继链。具体到Polkadot上,系统使用中继链来协调不同平行链的跨链操作。根据不同的商业环境,开发者可以使用Substrate开发和搭建不同的平行链。中继链的验证节点用于验证平行链区块的正确性从而保证每条平行链具有相同的的安全性,与此同时协调不同平行链之间的通信。一些已有的区块链,例如以太坊、比特币,暂时没有基于Substrate的平行链版本。目前的方法是使用桥,将它们桥接到平行链当中,再通过中继链与其它链进行沟通。
在这样的框架结构中,最中心的是中继链,它连接不同的平行链。刚刚提到桥接链,桥接链不是直接连到中继链上,而是通过一个桥,先连接到平行链,之后通过中继链跟其它链进行通信。
每个平行链都有中继链的轻节点,用来接收和验证中继链的消息。同时平行链有自己的校对节点称为collator。校对节点搜集对应平行链上的数据,将这些数据传递给中继链。中继链会分派不同的验证节点,去验证平行链上的区块是否是正确的,是否有双花的攻击,如果一些区块有问题,中继链会根据协议没收对应平行链插槽,或者对一些节点进行惩罚。
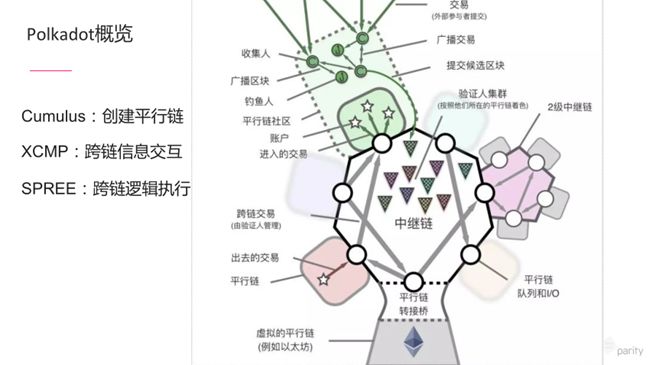
上图来自Polkadot的白皮书,将不同的角色都包含在里面,包括不同的平行链以及平行链里面是怎么运作的,如处理交易、广播交易以及最终交易写成区块,区块最后要写入到中继链里面等。
如果中继链想要支撑成千上万个平行链,那么我们如何实现更高的横向扩展呢?方法就是将二级中继链作为一个平行链接入到中继链里面,构建出一个更加分散的连接中继链的跨链平台。
目前Parity正在开发三个至关重要的功能。第一个是Cumulus。平行链需要一个连接器连接到中继链,这个连接器就是Cumulus。现在用Substrate开发出来的代码,未来只需要很少的改动,就可以使用Cumulus连接到中继链,前提是拿到对应的插槽。
第二个是XCMP跨链信息交互协议,不同的平行链如果想调用或者发送消息给其它的平行链,就需要通过这样一个协议去传输。
第三个是SPREE。讲到跨链,大家通常默认是资产跨链,资产A放在链B上面,做好一点可以做成去中心化的。再好一点就是现在提到的不同的链可以通过中继链或者其它的方法将信息发送过去,对方链可以执行对应的交易,或者智能合约。但前提是,不同的平行链他们是相对比较同态的架构。同构就是不同的平行链执行处理交易的逻辑是大致一样的。链A是用EVM处理智能合约,链B也是用EVM处理交易,那么链A发送交易给链B,链B是可以处理的。如果链A是EVM,链B是WASM,那么链B收到A的交易也不知道怎么处理。SPREE可以支持跨链执行代码的交互。就是链A将自己的执行逻辑进行打包,打包以后生成一个可执行的runtime通过一些渠道发送给链B,链B收到后可以去执行链A的交易。即使链A和B的处理交易的方式不同,因为B收到了A的代码和数据,那么B就可以处理A上的交易了。这三个功能都在紧锣密鼓的进行研发。之后有了这三个协议,我们进行任何的跨链交易和数据的处理操作。
在过去两年间,Substrate已经有超过20万行代码,还有很多的社区贡献者。在第一季度Substrate会从1.0升级到2.0版本,会有更好的性能以及更稳定的组件。同时,目前已经有超过80个团队基于Substrate/Polkadot进行开发。欢迎大家共同在Substrate/Polkadot上构建有意思的联盟链和平行链。
今天的分享就到这里,谢谢大家!
来源:万向区块链
编者注:原标题为《【万向区块链蜂巢学院第13期】贾瑶琪:Web3.0落地的必由之路—区块链的可扩展性和互操作性》。本文作了不改变作者原意的删减。
原创文章,作者:高天,如若转载,请注明出处:http://www.doubi.com/?p=5222